
[자바 ORM 표준 JPA 프로그래밍 - 기본편] 04강. 엔티티 매핑
04강. 엔티티 매핑
0. 엔티티 매핑 소개
- 객체와 테이블 매핑:
@Entity,@Table - 필드와 컬럼 매핑:
@Column - 기본 키 매핑:
@Id - 연관관계 매핑:
@ManyToOne,@JoinColumn- ex. 회원 - 소속 팀 연관 관계 매핑
- 1:1, 1:N ..
1. 객체와 테이블 매핑
@Entity
@Entity가 붙은 클래스 : JPA가 관리하는 엔티티(필수)- 데이터베이스 테이블과 매핑되는 클래스
- 없으면 JPA와 관련 없음
🚨 주의
- 기본 생성자 필수 (파라미터가 없는 public 또는 protected 생성자)
- JPA 구현해서 사용하는 라이브러리를 사용하려면 필요
- final 클래스, enum, interface, inner 클래스 사용X
- DB에 저장할 필드에 final 사용 X
@Table
@Table: 엔티티와 매핑할 테이블 지정
| 속성 | 기능 | 기본값 |
|---|---|---|
| name | 매핑할 테이블 이름 | 엔티티 이름 그대로 사용 (같은 클래스 이름 없으면 가급적 기본값 사용) |
| catalog | 데이터베이스 catalog 매핑 | |
| schema | 데이터베이스 schema 매핑 | |
| uniqueConstraints (DDL) | DDL 생성 시에 유니크 제약 조건 생성 |
-
name : 다른 이름으로 지정하고 싶은 경우
@Entity @Table(name = "MBR") // MBR 테이블과 매핑 public class Member { ... }
2. 데이터베이스 스키마 자동 생성
데이터베이스 스키마 자동 생성
- 테이블 중심 -> 객체 중심
- DDL을 애플리케이션 실행 시점에 자동 생성 (CREATE)
- 객체 매핑 알아서 해줌!
- 데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL 생성
- 이렇게 생성된 DDL은 개발 장비에서만 사용
- 운영서버에서는 사용하지 않거나, 필요하다면 적절히 다듬은 후 사용
1) 속성
hibernate.hbm2ddl.auto
| 옵션 | 설명 |
|---|---|
| create | - 기존테이블 삭제 후 생성 (DROP + CREATE) |
| create-drop | - create와 같으나 종료시점에 테이블 DROP - 보통 TC 실행해볼 때, 마지막에 지우기 위해 사용 |
| update | - 변경분만 반영(운영DB에는 사용하면 안됨) - 테이블 변경하는데 Drop 하지 않고 Alter 하고 싶을 때 사용 - 삭제는 안되고 추가만 가능 |
| validate | - 엔티티와 테이블이 정상 매핑되었는지만 확인 |
| none | - 속성을 사용하지 않음 |
ex. create
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<!-- 생략 -->
<!-- 옵션 -->
<!-- 생략 -->
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
</persistence-unit>
</persistence>
Member.java
@Entity
public class Member {
@Id // PK
private long id;
private String name;
private int age;
// 생성자 (기본 생성자 꼭!!)
// 생략
// getter, setter
// 생략
}
JpaMain.java 실행 결과 : Drop Table 후에 Create Table + DB에 데이터 없는 빈 테이블 생성됨
Hibernate:
drop table Member if exists
Hibernate:
create table Member (
id bigint not null,
age integer not null,
name varchar(255),
primary key (id)
)
ex. update
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<!-- 생략 -->
<!-- 옵션 -->
<!-- 생략 -->
<property name="hibernate.hbm2ddl.auto" value="update" />
</properties>
</persistence-unit>
</persistence>
Member.java
@Entity
public class Member {
@Id // PK
private long id;
private String name;
// 생성자 (기본 생성자 꼭!!)
// 생략
// getter, setter
// 생략
}
실행 결과
Hibernate:
create table Member (
id bigint not null,
name varchar(255),
primary key (id)
)
Member.java에 age 추가 후 다시 실행
Member.java
@Entity
public class Member {
@Id // PK
private long id;
private String name;
private int age;
// 생성자 (기본 생성자 꼭!!)
// 생략
// getter, setter
// 생략
}
실행 결과 : age column만 alter
Hibernate:
alter table Member
add column age integer not null
ex. validate
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<!-- 생략 -->
<!-- 옵션 -->
<!-- 생략 -->
<property name="hibernate.hbm2ddl.auto" value="validate" />
</properties>
</persistence-unit>
</persistence>
Member.java
@Entity
public class Member {
@Id // PK
private long id;
private String name;
private int gogo; // table에 없는 컬럼
// 생성자 (기본 생성자 꼭!!)
// 생략
// getter, setter
// 생략
}
실행 결과(에러)
Caused by: org.hibernate.tool.schema.spi.SchemaManagementException: Schema-validation: missing column [gogo] in table [Member]
2) 실습
- 스키마 자동 생성하기 설정
- 스키마 자동생성하기 실행, 옵션별 확인
-
데이터베이스 방언 별로 달라지는 것 확인(varchar)
ex. Oracle
persistence.xml
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.2" xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"> <persistence-unit name="hello"> <properties> <!-- 필수 속성 --> <!-- 생략 --> <!-- 옵션 --> <!-- 생략 --> <property name="hibernate.hbm2ddl.auto" value="create" /> </properties> </persistence-unit> </persistence>실행결과 : varchar2 : Oracle 방언
Hibernate: create table Member ( id number(19,0) not null, gogo number(10,0) not null, name varchar2(255 char), primary key (id) )
🚨 주의
- 운영 장비에는 절대 create, create-drop, update 사용하면 안됨!!!
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
- 혼자 쓰는 로컬 PC 아니면 가급적이면 사용하지 말기 : 필요하면 직접 script 써써 테스트
DDL 생성 기능
- 제약조건 추가: 회원 이름은 필수, 10자 초과X
@Column(nullable = false, length = 10)
ex.
Member.java
@Entity public class Member { @Id // PK private long id; @Column(unique = true, length = 10) private String name; private int age; }실행 결과
Hibernate: create table Member ( id bigint not null, age integer not null, name varchar(10), primary key (id) ) Hibernate: alter table Member add constraint UK_ektea7vp6e3low620iewuxhlq unique (name) - 유니크 제약조건 추가
@Table(uniqueConstraints = {@UniqueConstraint( name = "NAME_AGE_UNIQUE", columnNames = {"NAME", "AGE"})})
- DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다
3. 필드와 컬럼 매핑
예제. 요구사항 추가
- 회원은 일반 회원과 관리자로 구분해야 한다.
- 회원 가입일과 수정일이 있어야 한다.
- 회원을 설명할 수 있는 필드가 있어야 한다. 이 필드는 길이 제한이 없다.
Member.java
@Entity
public class Member {
@Id // PK 지정
private Long id;
@Column(name = "name") // DB에서는 name과 매핑
private String username;
private Integer age;
@Enumerated(EnumType.STRING) // java에는 EnumType이 있는데 DB에는 없음 -> @Enumerated
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP) // 날짜 타입은 @Temporal
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob // VARCHAR를 넘는 큰 컨텐츠. 이 때 문자타입이면 clob으로 생성됨
private String description;
public Member() {}
//Getter, Setter…
}
RoleType.java
package hellojpa;
public enum RoleType {
USER, ADMIN
}
실행결과
Hibernate:
create table Member (
id bigint not null,
age integer,
createdDate timestamp,
description clob,
lastModifiedDate timestamp,
roleType varchar(255),
name varchar(255),
primary key (id)
)
매핑 어노테이션 정리
hibernate.hbm2ddl.auto
| 어노테이션 | 설명 |
|---|---|
| @Column | 컬럼 매핑 |
| @Temporal | 날짜 타입 매핑 |
| @Enumerated | enum 타입 매핑 |
| @Lob | BLOB, CLOB 매핑 |
| @Transient | 특정 필드를 컬럼에 매핑하지 않음 (매핑 무시, DB와 관계 없고 메모리에서만 사용) |
💡 Temporal : DATE, TIME, TIMESTAMP
- 날짜 타입은
@Temporal- Java의 날짜 타입은 날짜+시간 포함되어있지만, DB에서는 이를 구분해서 사용
- Date : 날짜 / Time : 시간 / Timestamp : 날짜 + 시간
@Column
| 속성 | 설명 | 기본값 |
|---|---|---|
| name | - 필드와 매핑할 테이블의 컬럼 이름 | 객체의 필드 이름 |
| insertable, updatable | - 등록(insert), 변경(update) 가능 여부 | TRUE |
| ⭐️ nullable(DDL) | - null 값의 허용 여부를 설정 - false : DDL 생성 시에 not null 제약조건 |
|
| unique(DDL) | - @Table의 uniqueConstraints와 같지만 한 컬럼에 간단히 유니크 제약조건을 걸 때 - 잘 사용하지 않음. 제약조건 이름이 랜덤으로 생성되어 운영시에 활용 어렵기 때문. 보통 @Table에서 제약조건 이름까지 설정 |
|
| columnDefinition(DDL) | - 데이터베이스 컬럼 정보를 직접 줄 때 - 작성한 내용이 그대로 DDL에 들어감 |
|
| ex) varchar(100) default ‘EMPTY’ | 필드의 자바 타입과 방언 정보를 사용해 | |
| length(DDL) | - 문자 길이 제약조건, String 타입에만 사용 | 255 |
| precision, scale(DDL) | - BigDecimal, BigInteger 타입에서 사용 - precision : 소수점을 포함한 전체 자릿수 scale : 소수의 자릿수 - double, float 타입에는 적용되지 않고, 아주 큰 숫자나 정밀한 소수를 다루어야 할 때만 사용 |
precision=19, scale=2 |
@Enumerated
- 자바 enum 타입을 매핑할 때 사용
| 속성 | 설명 | 기본값 |
|---|---|---|
| value | • EnumType.ORDINAL: enum 순서를 DB에 저장 • EnumType.STRING: enum 이름을 DB에 저장 |
EnumType.ORDINAL |
🚨 enum에서 ORDINAL 사용X 무조건 STRING !!!
- enum이 수정되는 경우 문제가 발생할 가능성이 높음
ex.
Member.java
@Entity public class Member { @Id private Long id; @Column(name = "name", nullable = false) // DB에서는 name과 매핑 private String username; private Integer age; @Enumerated(EnumType.ORDINAL) private RoleType roleType; @Temporal(TemporalType.TIMESTAMP) private Date createdDate; @Temporal(TemporalType.TIMESTAMP) private Date lastModifiedDate; @Lob private String description; public Member() {} //Getter, Setter… (생략(필수)) }RoleType.java : enum 타입
package hellojpa; public enum RoleType { USER, ADMIN }실행하여 (Id, Username, RoleType) = (1L, “A”, USER), (2L, “B”, ADMIN) 두 행 넣음
DB에는
ID AGE CREATEDATE DESCRIPTION LASTMODIFIEDDATE ROLETYPE NAME 2 null null null null 1 B 1 null null null null 0 A RoleType.java에 GUEST 추가
RoleType.java
package hellojpa; public enum RoleType { GUEST, USER, ADMIN }실행하여 (Id, Username, RoleType) = (3L, “C”, GUEST) 추가하면..
실행 결과 DB
ID AGE CREATEDATE DESCRIPTION LASTMODIFIEDDATE ROLETYPE NAME 3 null null null null 0 C 2 null null null null 1 B 1 null null null null 0 A -> Id 3과 1의 RoleType은 다름에도 같은 0으로 저장됨 (변경 사항이 적용되지 않음)
@Temporal
-
날짜 타입(java.util.Date, java.util.Calendar)을 매핑할 때 사용
속성 설명 기본값 value - TemporalType.DATE: 날짜, 데이터베이스 date 타입과 매핑 (예: 2013–10-11)
- TemporalType.TIME: 시간, 데이터베이스 time 타입과 매핑 (예: 11:11:11)
- TemporalType.TIMESTAMP: 날짜와 시간, 데이터베이스 timestamp 타입과 매핑(예: 2013–10–11 11:11:11)
💡 LocalDate, LocalDateTime을 사용할 때는 생략 가능(최신 하이버네이트 지원) - Java 8 부터
- LocalDate : 년월까지만
- LocalDateTime : 년월시간까지
ex.
private LocalDate testLocalDate; // -> DB에 date 로 생성 private LocalDateTime testLocalDateTime; // DB에 timestamp로 생성
@Lob
@Lob에는 지정할 수 있는 속성이 없음-
매핑하는 필드 타입이 문자면 CLOB 매핑, 나머지는 BLOB 매핑
매핑 타입 상세 CLOB String, char[], java.sql.CLOB BLOB byte[], java.sql. BLOB
@Transient
- 필드 매핑X
- 데이터베이스에 저장X, 조회X
- 주로 메모리상에서만 임시로 어떤 값을 보관하고 싶을 때 사용
@Transient
private Integer temp;
4. 기본 키 매핑
기본 키 매핑 어노테이션
@Id@GeneratedValue
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
기본 키 매핑 방법
- 직접 할당:
@Id만 사용 ex. ID_A 로 세팅 -
자동 생성(
@GeneratedValue)Type 상세 IDENTITY - 데이터베이스에 위임, MYSQL SEQUENCE - 데이터베이스 시퀀스 오브젝트 사용, ORACLE
-@SequenceGenerator필요TABLE - 키 생성용 테이블 사용, 모든 DB에서 사용
-@TableGenerator필요AUTO - 방언에 따라 자동 지정, 기본값 ex.
@Id @GeneratedValue(strategy = GenerationType.IDENTITY) private String id;
1) IDENTITY 전략
- 특징
- 기본 키 생성을 데이터베이스에 위임
- 주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용 (ex. MySQL의 AUTO_ INCREMENT)
- 단점 : em.persist 시점에 즉시 INSERT SQL 실행하고 DB에서 식별자를 조회 -> 모아서 insert 불가능
- JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행
-
그러나, AUTO_ INCREMENT는 데이터베이스에 INSERT SQL을 실행한 이후에 ID 값을 알 수 있음
즉, DB에 값이 입력되어야 PK인 ID 값을 알 수 있어서 1차 캐시의
@Id에 값을 넣을 수 없음 - 따라서, IDENTITY 전략에서만 em.persist를 호출한 시점에 바로 insert 쿼리를 날리고 DB에서 생성한 값을 읽어옴. 이 때, SELECT 쿼리 X
- JDBC 드라이버에 값 넣고 바로 return 받도록 짜여져 있음
Member.java
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name", nullable = false) // DB에서는 name과 매핑
private String username;
public Member() {}
//Getter, Setter…
}
JpaMain.java
public class JpaMain {
public static void main(String[] args) {
// 생략
try {
Member member = new Member();
member.setUsername("C");
System.out.println("================");
em.persist(member);
System.out.println("member.id = " + member.getId());
System.out.println("================");
tx.commit();
}
// 생략
}
}
실행 결과 : commit 이 아닌 persist에서 insert sql 실행
================
Hibernate:
/* insert hellojpa.Member
*/ insert
into
Member
(id, name)
values
(null, ?)
member.id = 1
================
-
매핑
@Entity public class Member { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id;
ex.
persistence.xml : 방언 MySQL로 설정
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5Dialect"/>
Member.java
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private String id;
@Column(name = "name", nullable = false)
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob
private String description;
public Member() {}
//Getter, Setter…
}
실행 결과 : id는 null auto_increment. 이때, JpaMain.java에서 id는 세팅하지 않음
Hibernate:
create table Member (
id varchar(255) not null **auto_increment**,
age integer,
createdDate datetime,
description longtext,
lastModifiedDate datetime,
roleType varchar(255),
name varchar(255) not null,
primary key (id)
) engine=MyISAM
참고. 방언 H2로 설정한 경우 쿼리 : id 값이 null로 들어감 (GeneratedValue가 들어가므로)
Hibernate:
/* insert hellojpa.Member
*/ insert
into
Member
(id, age, createdDate, description, lastModifiedDate, roleType, name)
values
(null, ?, ?, ?, ?, ?, ?)
2) SEQUENCE 전략
- 특징
- 데이터베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한 데이터베이스 오브젝트
- Oracle, PostgreSQL, DB2, H2 데이터베이스에서 사용 ex. Oracle Sequence
-
매핑
ex.
Member.java
@Entity @SequenceGenerator( name = “MEMBER_SEQ_GENERATOR", sequenceName = “MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름 initialValue = 1, allocationSize = 1) public class Member { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR") private Long id;JpaMain.java
public class JpaMain { public static void main(String[] args) { // 생략 try { Member member = new Member(); member.setUsername("C"); System.out.println("================"); em.persist(member); System.out.println("member.id = " + member.getId()); System.out.println("================"); tx.commit(); } // 생략 } }실행 결과
Hibernate: drop table Member if exists Hibernate: drop sequence if exists MEMBER_SEQ Hibernate: create sequence MEMBER_SEQ start with 1 increment by 1 // 1부터 시작하고 1 씩 증가시킴 Hibernate: create table Member ( id bigint not null, name varchar(255) not null, primary key (id) ) ================ Hibernate: call next value for MEMBER_SEQ // MEMBER_SEQ의 다음 값 줘 member.id = 1 // 그렇게 얻은 값이 1 ================ Hibernate: /* insert hellojpa.Member */ insert into Member (name, id) values (?, ?) -
@SequenceGenerator속성 설명 기본값 name - 식별자 생성기 이름 필수 sequenceName - 데이터베이스에 등록되어 있는 시퀀스 이름 hibernate_sequence initialValue - DDL 생성 시에만 사용됨
- 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정1 allocationSize - 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨)
- 데이터베이스 시퀀스 값이 하나씩 증가하도록 설정되어 있으면 이 값을 반드시 1로 설정⭐️ 50 catalog, schema - 데이터베이스 catalog, schema 이름 - SEQUENCE 전략과 최적화 : allocationSize 이용 (참고)
- SEQUENCE 전략의 문제점 : 시퀀스를 통해 식별자를 조회하기 위해 DB와 2번 통신
- 식별자를 구하기 위해 DB 시퀀스를 조회
- 조회한 시퀀스를 PK로 DB에 저장
-> 시퀀스에의 접근 횟수를 줄이기 위해 allocationSize 사용
: allocationSize 만큼 한 번에 시퀀스 값을 증가시키고, 메모리에 그만큼의 시퀀스 값을 할당
ex. allocationSize의 기본값 : 50
- 시퀀스 1회 조회시에 50을 증가 -> 1 ~ 50 까지 메모리에서 식별자를 할당
- 51에 도달하면 100까지 증가시키고, 51 ~ 100 까지 메모리에서 식별자를 할당
- SEQUENCE 전략의 문제점 : 시퀀스를 통해 식별자를 조회하기 위해 DB와 2번 통신
ex.
테이블 생성
Member.java
@Entity
@SequenceGenerator(
name = "MEMBER_SEQ_GENERATOR",
sequenceName = "MEMBER_SEQ",
initialValue = 1, allocationSize = 50)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR")
private Long id;
@Column(name = "name", nullable = false)
private String username;
public Member() {}
//Getter, Setter…
}
JpaMain.java
public class JpaMain {
public static void main(String[] args) {
// 생략
try {
tx.commit();
}
// 생략
}
}
실행 결과
Hibernate: create sequence MEMBER_SEQ start with 1 increment by 50
Hibernate:
create table Member (
id bigint not null,
name varchar(255) not null,
primary key (id)
)
DB

현재 값 -49, 증가 50 -> 한 번 호출하면 1
call next value for MEMBER_SEQ; 실행하면 NEXT VALUE FOR PUBLIC.MEMBER_SEQ = 1
member1만 persist
JpaMain.java
public class JpaMain {
public static void main(String[] args) {
// 생략
try {
Member member1 = new Member();
member1.setUsername("A");
Member member2 = new Member();
member2.setUsername("B");
Member member3 = new Member();
member3.setUsername("C");
System.out.println("================");
em.persist(member1);
System.out.println("member1 = " + member1.getId());
System.out.println("================");
tx.commit();
}
// 생략
}
}
실행결과
================
Hibernate:
call next value for MEMBER_SEQ // DB SEQ = 1
Hibernate:
call next value for MEMBER_SEQ // DB SEQ = 51
member1 = 1
================
Hibernate:
/* insert hellojpa.Member
*/ insert
into
Member
(name, id)
values
(?, ?)
메모리에서 50개씩 호출해야하는데, 처음 호출하니까 1 -> 문제가 있나? 하고 한 번 더 호출해서 51
DB SEQ = 1 / Application = 1
DB SEQ = 51 / Application = 2
DB SEQ = 51 / Application = 3
JpaMain.java
public class JpaMain {
public static void main(String[] args) {
// 생략
try {
Member member1 = new Member();
member1.setUsername("A");
Member member2 = new Member();
member2.setUsername("B");
Member member3 = new Member();
member3.setUsername("C");
System.out.println("================");
em.persist(member1); // 1, 51
em.persist(member2); // MEM
em.persist(member3); // MEM
System.out.println("member1 = " + member1.getId());
System.out.println("member2 = " + member2.getId());
System.out.println("member3 = " + member3.getId());
System.out.println("================");
//tx.commit();
}
// 생략
}
}
실행 결과
================
Hibernate:
call next value for MEMBER_SEQ // 1 맞춤
Hibernate:
call next value for MEMBER_SEQ // 51까지 미리 확보
member1 = 1
member2 = 2
member3 = 3
================
51 만나는 순간, 미리 next call 확보해야 해서 100까지 가져옴
💡 Integer vs. Long
- Integer, Long이 숫자 공간으로 2배 정도 차이 나지만 성능에 거의 영향을 주지 않음
- 10억이 넘을 때 타입을 바꾸는게 오히려 더 어려움. 따라서 Long 사용을 권장
3) TABLE 전략
- 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀀스를 흉내내는 전략
- 장점: 모든 데이터베이스에 적용 가능
- 단점: 성능 (ex. SEQUENCE는 시퀀스 생성에 최적화. 테이블은 그렇지 않음)
ex.
Member.java
@Entity
@TableGenerator(
name = "MEMBER_SEQ_GENERATOR",
table = "MY_SEQUENCES",
pkColumnValue = “MEMBER_SEQ", allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.TABLE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;
실행 결과
create table MY_SEQUENCES (
sequence_name varchar(255) not null,
next_val bigint,
primary key ( sequence_name )
)
DB : MY_SEQUENCES table
| SEQUENCE_NAME | NEXT_VAL |
|---|---|
| MEMBER_SEQ | 1 |
MEMBER_SEQ에 다음 들어올 값이 1
DB : MEMBER table
| ID | NAME |
|---|---|
| 1 | C |
MEMBER_SEQ의 NEXT_VAL 값이 ID에 들어옴
-
@TableGenerator의 속성속성 설명 기본값 name 식별자 생성기 이름 필수 table 키생성 테이블명 hibernate_sequences pkColumnName 시퀀스 컬럼명 sequence_name valueColumnNa 시퀀스 값 컬럼명 next_val pkColumnValue 키로 사용할 값 이름 엔티티 이름 ⭐️ initialValue 초기 값, 마지막으로 생성된 값이 기준이다. 0 ⭐️ allocationSize 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨) 50 catalog, schema 데이터베이스 catalog, schema 이름 uniqueConstraints(DDL) 유니크 제약 조건을 지정할 수 있다
권장하는 식별자 전략
- 기본 키 제약 조건 : not null, 유일, ⭐️ 변하면 안됨
- 그러나 미래까지 이 조건을 만족하는 자연키 찾기 어려움 -> 대리키(대체키) 사용
- 자연키 : 비즈니스적으로 의미 있는 키 ex. 주민등록번호, 전화번호 등
- 대리키(대체키) : GeneratedValue, Random 값 등 비즈니스와 관계 없는 키 사용 권장
-
주민등록번호도 기본 키로 적절하기 않음
ex. 국가에서 주민등록번호를 보관을 금지해서 주민등록번호를 PK로 사용하던 테이블들 대공사..
- 권장: Long형(10억 넘어도 동작하도록) + 대체키 + 키 생성전략 사용
5. 실전 예제 - 1. 요구사항 분석과 기본 매핑
요구사항 분석
- 회원은 상품을 주문할 수 있다.
- 주문 시 여러 종류의 상품을 선택할 수 있다
기능 목록
- 회원 기능 : 회원등록, 회원조회
- 상품 기능 : 상품등록, 상품수정, 상품조회
- 주문 기능 : 상품주문, 주문내역조회, 주문취소
도메인 모델 분석
- 회원과 주문의 관계: 회원은 여러 번 주문할 수 있다. (일대다)
- 주문과 상품의 관계: 주문할 때 여러 상품을 선택할 수 있다. 반대로 같은 상품도 여러 번 주문될 수 있다. 주문상품 이라는 모델을 만들어서 다대다 관계를 일다대, 다대일 관계로 풀어냄
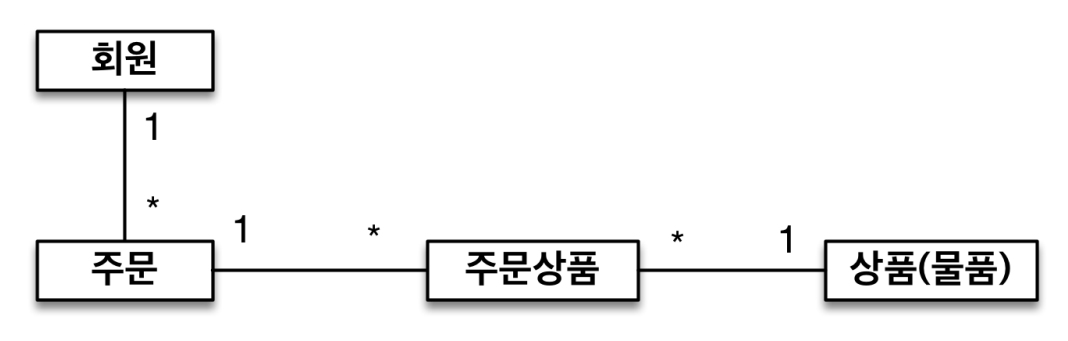
테이블 설계
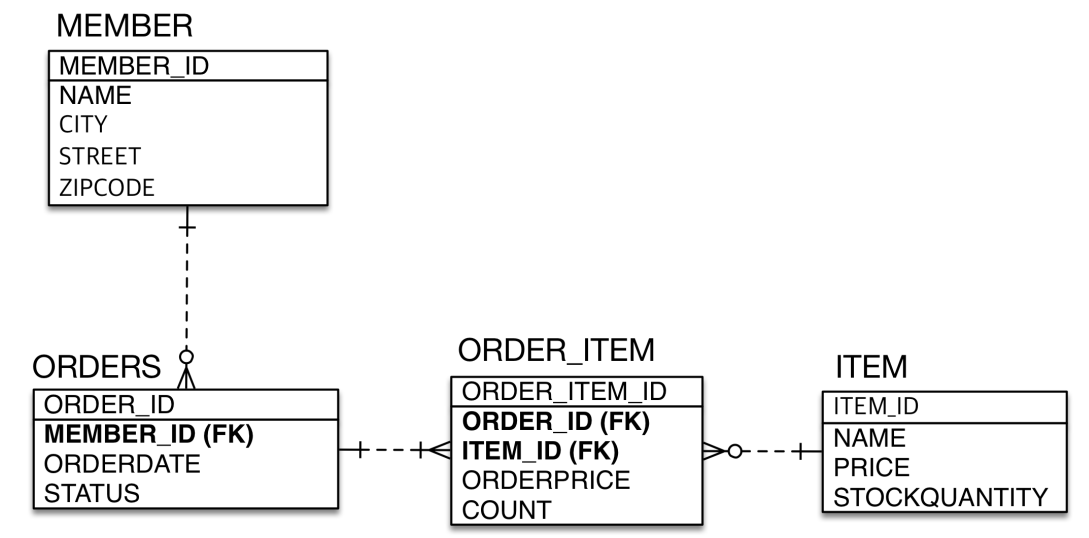
엔티티 설계와 매핑
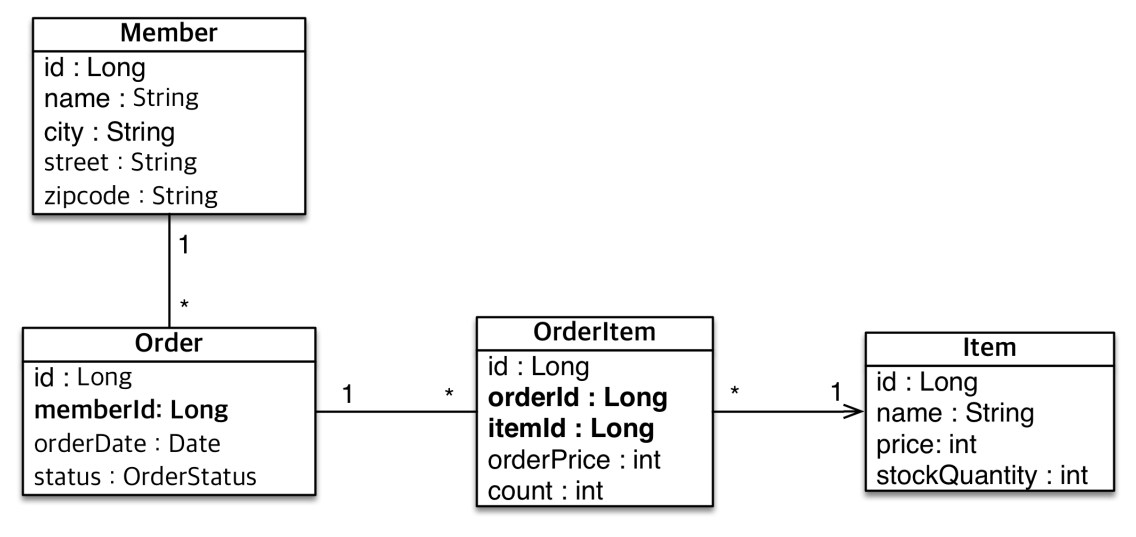
🚨 주의 사항
- 설정 사항 가져오기 : pom.xml, persistence.xml
- 객체 만들기
@Entity반드시!!- setter 만들때는 주의! 아무 곳에서나 set할 수 있게 되어 추적 어려워짐. 가급적이면 생성자에서 다 세팅하고 setter의 사용을 최소화
- 날짜시간 유형은 LocalDate, LocalDateTime (Java 8 ~)
- enum 타입은 반드시
@Enumerated(EnumType.STRING)- 객체와 테이블명 다른 경우
@Table(name = “<table명>”)
- ex. 객체명이 DB의 예약어여서 테이블 명으로 사용 불가능한 경우 ex. ORDER(DB의 Order By) - 객체의 속성명과 컬럼명 다른 경우
@Column(name = “<Column명>”)
💡 SpringBoot는 hiberante JPA 이용하면 Camel Case를 Underscore로 바꾸어 줌 ex. orderDate -> order_date
데이터 중심 설계
- 객체를 관계형 DB에 그대로 맞춰서 설계
Member.java
@Entity
public class Member {
@Id @GeneratedValue // 생략하면 AUTO
@Column(name = "MEMBER_ID")
private Long id;
private String name;
private String city;
private String street;
private String zipcode;
// getter, setter
// 생략
}
Order.java
@Entity
@Table(name = "ORDERS") // DB에는 ORDER가 예약어여서(ORDER BY) 사용 불가능한 경우도 있음
public class Order {
@Id @GeneratedValue
@Column(name = "ORDER_ID")
private Long id;
@Column(name = "MEMBER_ID")
private Long memberId; // 누가 주문했는지
// private Member member; // 더 객체지향적으로 짜려면 이런 식으로..
private LocalDateTime orderDate;
@Enumerated(EnumType.STRING)
private OrderStatus status; // ORDER, CANCEL
// getter, setter
// 생략
}
OrderStatus.java
public enum OrderStatus {
ORDER, CANCEL
}
Item.java
@Entity
public class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID") // table의 컬럼명은 ITEM_ID
private Long id;
private String name;
private int price;
private int stackQuantity;
// getter, setter
// 생략
}
OrderItem.java
@Entity
public class OrderItem {
@Id @GeneratedValue
@Column(name = "ORDER_ITEM_ID")
private Long id;
@Column(name = "ORDER_ID")
private Long orderId;
@Column(name = "ITEM_ID")
private Long itemId;
private int orderPrice;
private int count;
// getter, setter
// 생략
}
데이터 중심 설계의 문제점
- 현재 방식은 객체 설계를 테이블 설계에 맞춘 방식
- 테이블의 외래키를 객체에 그대로 가져옴
- 객체 그래프 탐색이 불가능
- 참조가 없으므로 UML도 잘못됨
-> 연관관계 매핑 필요!
ex. 위 실습 코드에서 ..
Order의 주문한 memberId로 Member를 찾고자 하는 경우 -> 객체 지향적이지 않음!
JpaMain.java
public class JpaMain {
public static void main(String[] args) {
// 생략
try {
Order order = em.find(Order.class, 1L);
Long memberId = order.getMemberId(); // order에서 memberId 찾음
Member member = em.find(Member.class, memberId); // memberId 이용해서 또 member를 찾아주어야 함 (memberId 찾는다고 바로 member를 찾을 수 있는 것이 아니라)
tx.commit();
}
// 생략
}
}
Leave a comment